

AI is writing more of our code than ever. Once it is committed, we lose visibility into where it came from and how much scrutiny it received.
Agent Blame adds line-level AI attribution to your repo and carries that attribution forward with commits, so you can review and debug with better context and you can measure adoption with real numbers.
Git blame tells you who committed a line. It does not tell you whether the line was human-authored or produced by an agent.
This creates real problems:
- Code review becomes guesswork. Was this logic intentionally designed, or accepted without scrutiny?
- Debugging loses context. Provenance changes how you investigate failures.
- Evaluating AI tools is vibes. Is Claude better than GPT-4 for your codebase? Without data, you're guessing.
- Knowledge transfer suffers. Junior devs learn from codebases. Are they absorbing an engineer's intent or an AI's defaults?
What we Built
At Mesa, we built Agent Blame to make AI-assisted code visible after it lands in git.
Agent Blame has two surfaces:
CLI
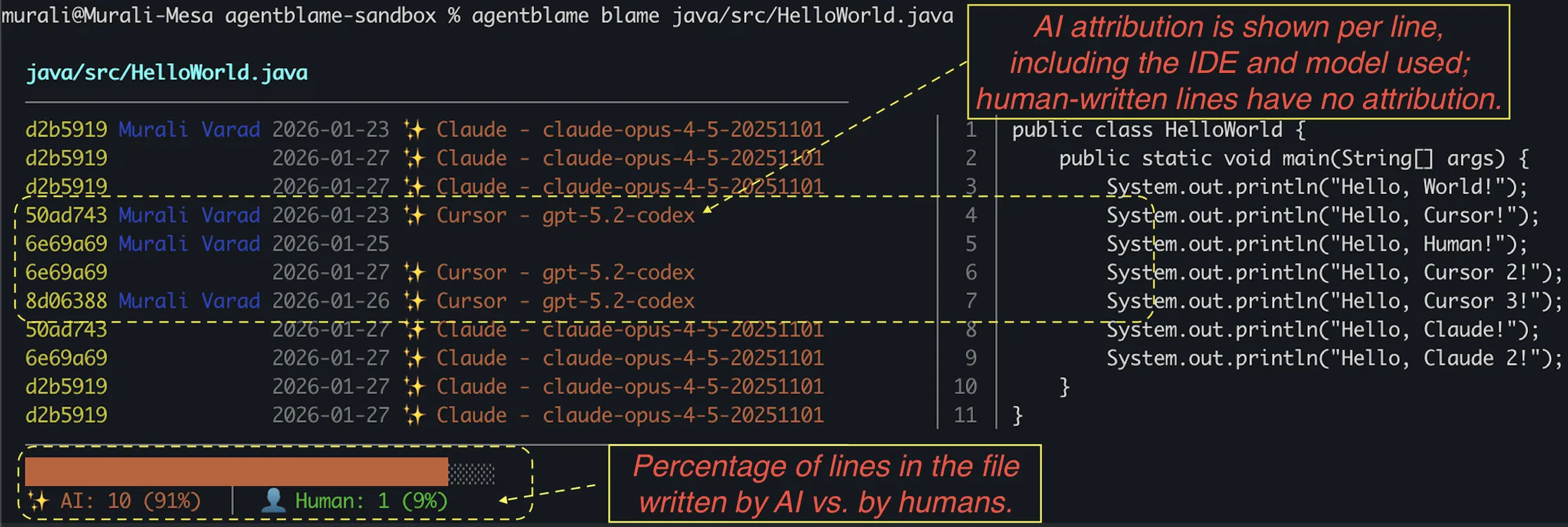
Line-level attribution in the terminal by combining git blame with attribution stored in git notes.
- In the screenshot, attribution appears next to each AI-written line, including the IDE and model used; human-written lines are unmarked.
- In the screenshot footer, we display the AI vs. human composition for the file as a percentage.
Chrome Extension
The Chrome extension brings attribution into GitHub in two places.
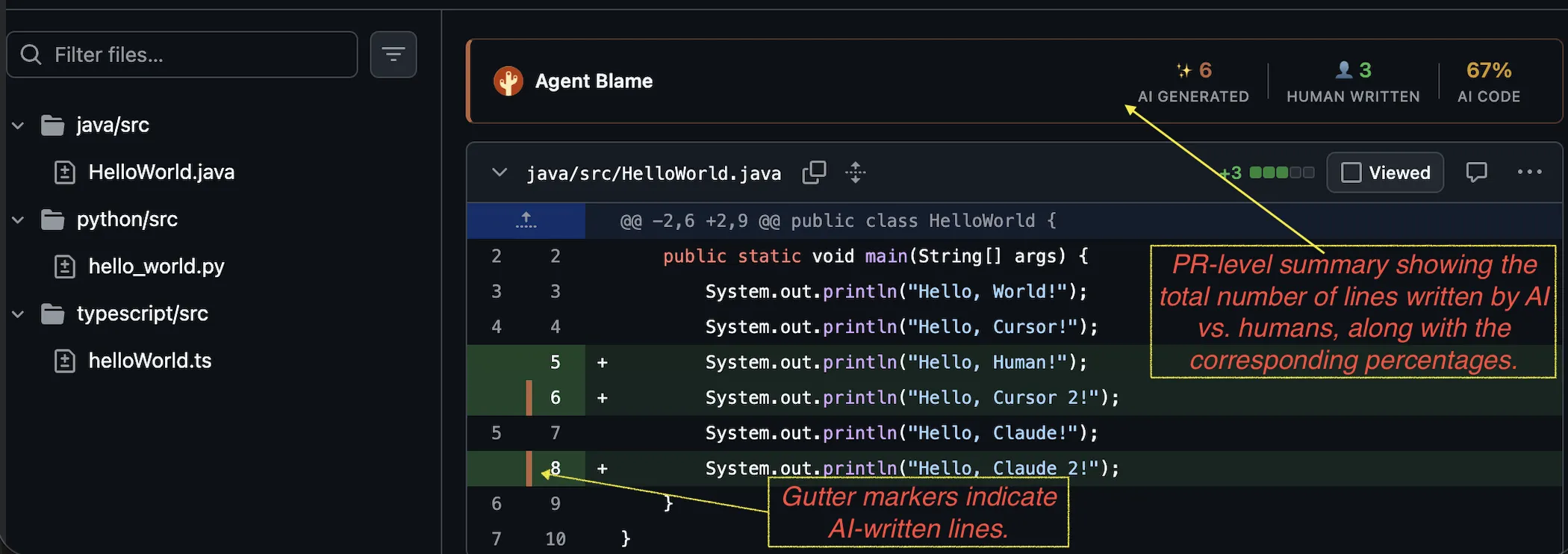
PR Line Markers
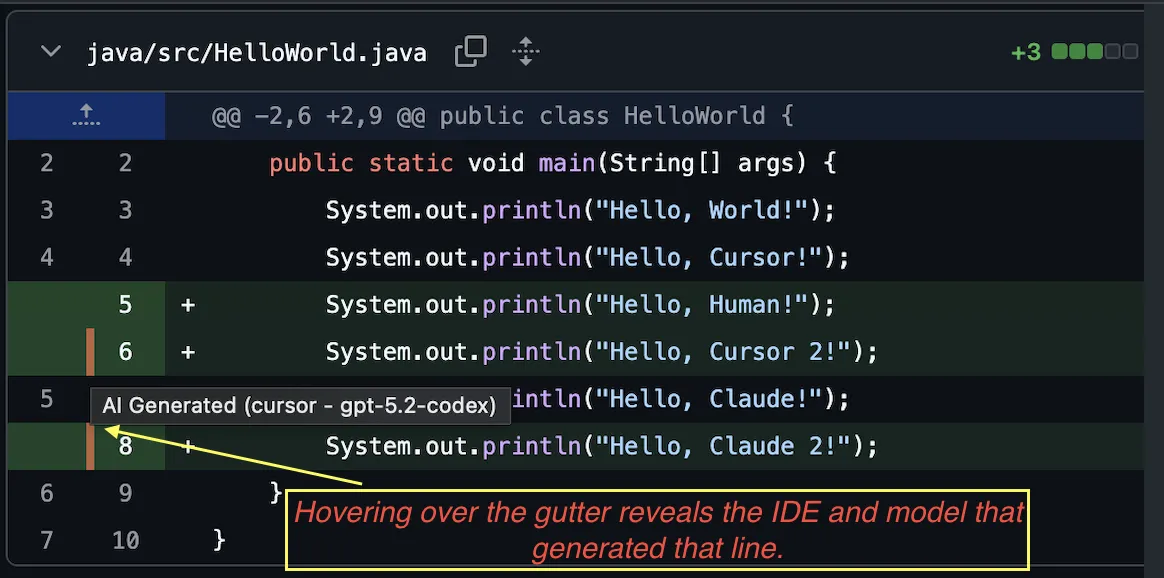
Inline markers in GitHub PR diffs. Hover shows provider, model, and confidence. Also shows a PR-level summary, including AI percentage.
Analytics Dashboard
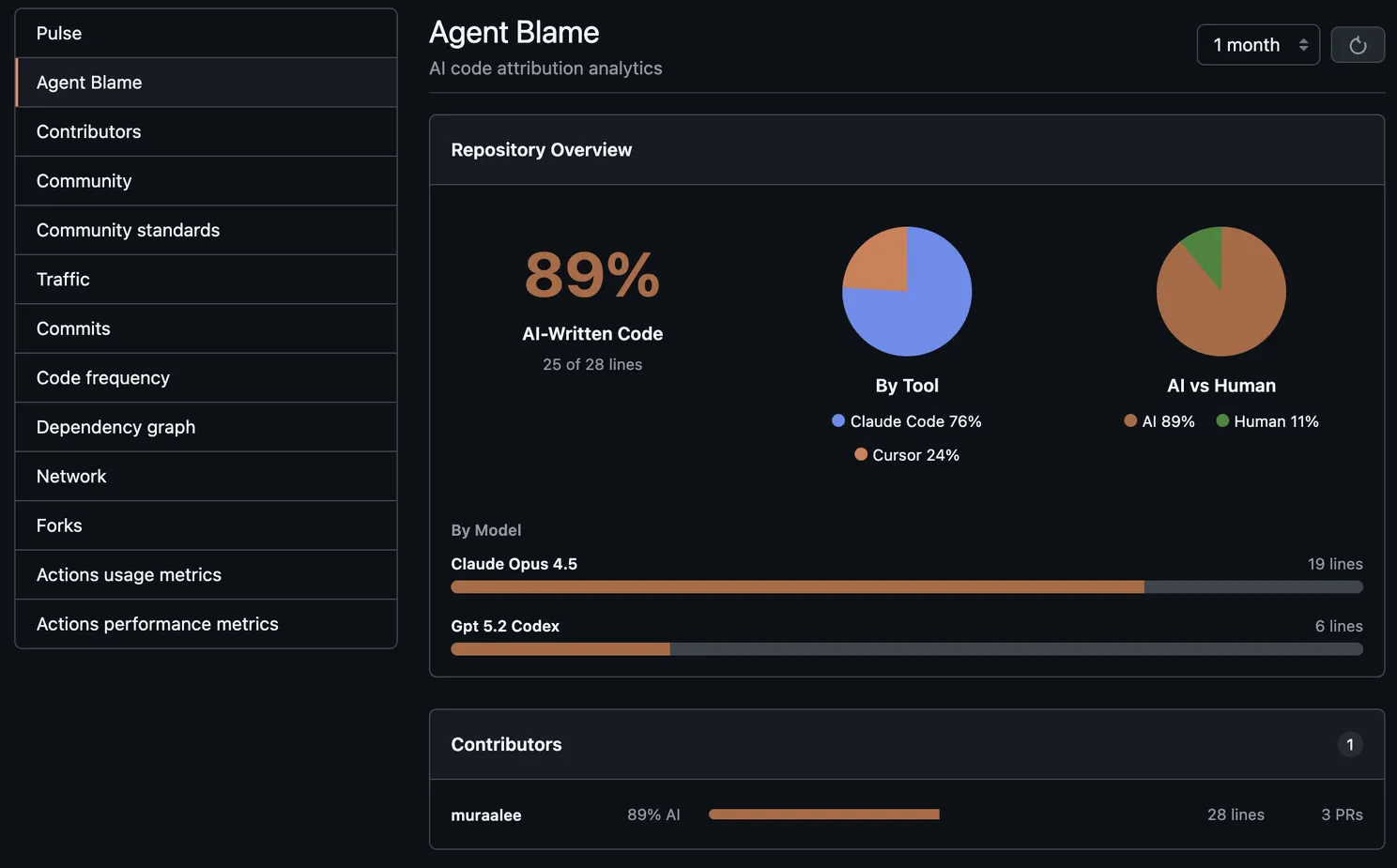
A repo-level view in GitHub Insights that tracks AI percentage and trends, broken down by tool, model, and contributor.
- Repository-wide AI percentage
- Breakdown by tool (Cursor vs Claude Code vs OpenCode)
- Breakdown by model (GPT-4o, Claude Opus, Sonnet, etc.)
- Per-contributor statistics
- PR history with trends
All updated automatically on merge.
How it actually works
This is not a "detector." We don't guess after the fact whether a line looks AI-written.
Instead, we capture provenance at the moment an agent edits a file, then attach that provenance to what lands in git.
Two constraints shaped everything:
- No backend: Attribution lives with the code and is readable from a clone.
- Precision-first: We'd rather miss attribution than incorrectly label human-authored work.
Here's the end-to-end pipeline:

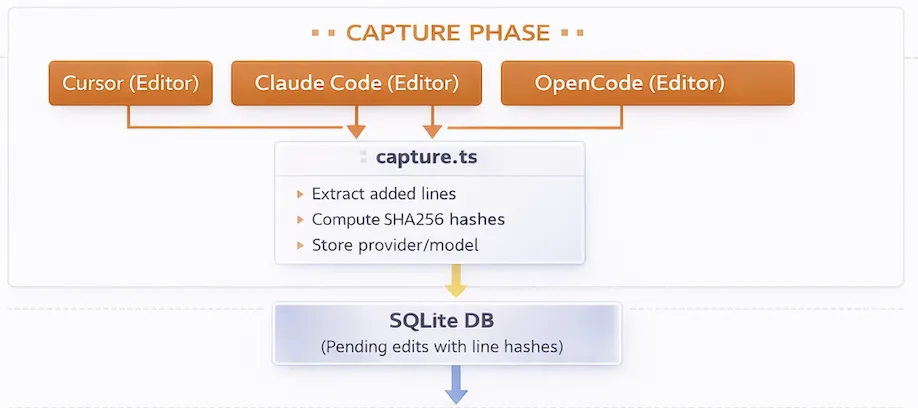
Capture Phase
Cursor, Claude Code, and OpenCode expose hooks that fire when an agent edits a file. We intercept those events. Each tool gives slightly different raw data (strings vs patches vs full file snapshots), so we normalize them into the same internal representation: the set of newly added lines.
For each added line, we compute two SHA256 hashes:
- An exact hash
- A normalized hash with whitespace stripped
We store those hashes in a local SQLite database as pending edits. At this point, the agent produced the line, but it has not been committed.
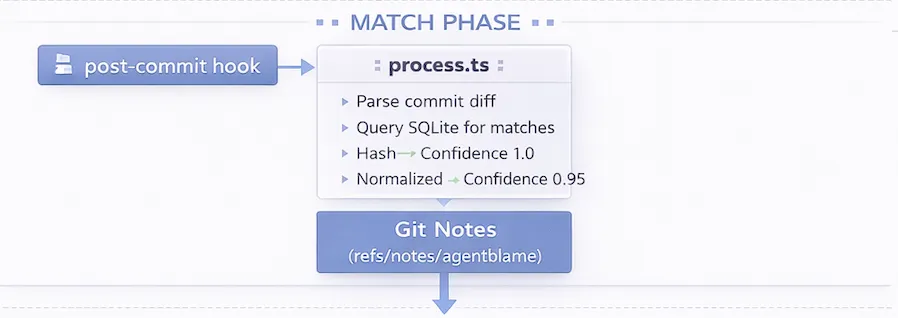
Match Phase
On commit, a post-commit hook parses the commit diff, finds which lines were actually added, hashes them, and looks them up in the pending-edit store.
Matching rules:
- Exact match → confidence 1.0
- Normalized match → confidence 0.95
When we find a match, we write attribution to git notes for that commit: file path, line range, provider, model, and confidence.
Analytics Phase
A GitHub Actions workflow runs on merge. It addresses the practical problem that squash and rebase merges create new commit SHAs, which can otherwise orphan attribution.
On merge, the workflow:
- Detects merge type (merge commit vs squash vs rebase)
- Transfers attribution to the final commit(s) using content-based matching
- Aggregates metrics (AI lines vs total added lines), with breakdowns by provider, model, and contributor
- Writes aggregates into a stable notes ref so the analytics surface can render trends over time

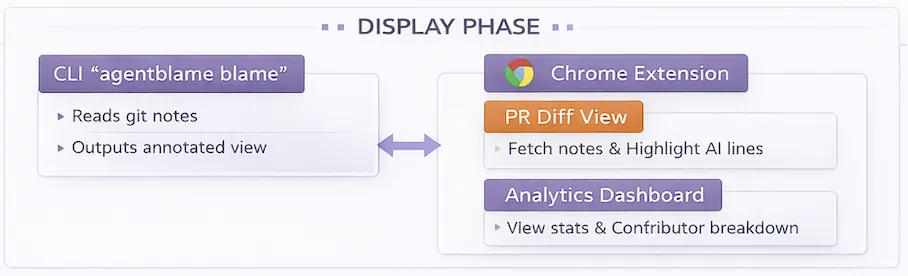
Display Phase
Everything reads from git:
- The CLI merges git blame output with git notes attribution
- The Chrome extension fetches notes and injects markers into PR diffs
- The dashboard reads aggregate notes and renders trends in GitHub Insights
Nothing requires a separate backend, and nothing needs to phone home.
Why this architecture?
There are two obvious ways to build attribution:
- A centralized service + database that receives events and serves attribution back.
- A repo-native approach where attribution travels with the code.
A service makes cross-repo analytics and policy enforcement easier, but it also becomes a dependency: accounts, availability, data retention, security reviews, and a "source of truth" that lives outside the repo.
We picked the repo-native route for a simple reason: provenance should be inspectable wherever the code is inspectable. If you can clone a repo, you should be able to answer "where did this come from?" without logging into anything or being online.
Why git notes
Git notes let us attach metadata to commits without rewriting history. They're first-class git objects (refs pointing to objects), which means attribution is:
- versioned and reviewable,
- compatible with existing git tooling,
- and auditable in the same way as the code it annotates.
Operational reality: notes are refs, so they propagate like refs. Teams can either push/fetch the notes ref explicitly, or configure remotes to include it by default. When notes aren't available, the UI degrades to "unknown" rather than guessing.
Design principle: precision over recall
Agent Blame is intentionally conservative. If you rename variables, restructure logic, or rework AI output before it hits git, the final code is human-authored and reviewed from the repository's perspective. We treat it that way.
That principle drives the matcher: false attribution is worse than missing attribution. So we will miss some cases by design:
- heavily edited output won't match,
- changes introduced outside hook capture won't be attributed.
Those misses are acceptable because the system's value comes from trustworthy signals in review, not perfect coverage.
Agent Blame is open source
We would love feedback, especially if you find edge cases that break things.